Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right tool.
Build reliable AI apps together with Agenta's open-source LLMOps platform!.
Last updated: March 1, 2026
OpenMark AI lets you benchmark over 100 LLMs for your specific tasks, revealing the best model based on cost, speed, quality, and stability!.
Last updated: March 26, 2026
Visual Comparison
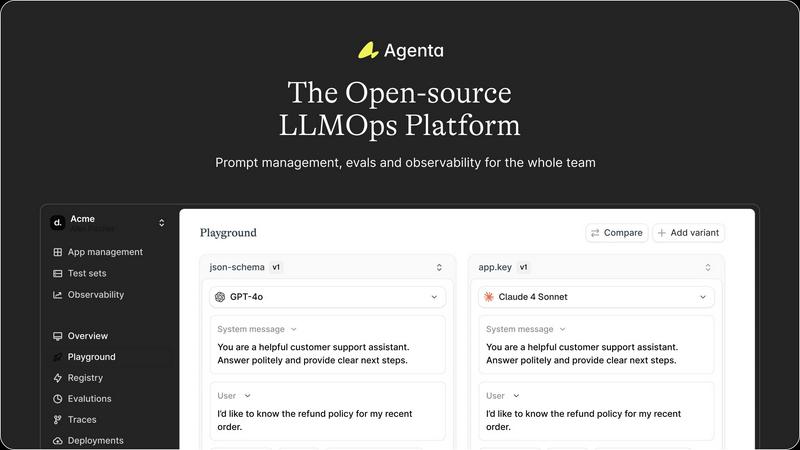
Agenta
OpenMark AI

Feature Comparison
Agenta
Unified Playground & Experimentation
Agenta provides a powerful, unified playground where your entire team can experiment with prompts and models side-by-side in real-time! This central hub eliminates scattered workflows, allowing you to iterate quickly with complete version history for every change. It's model-agnostic, so you can leverage the best models from any provider without fear of vendor lock-in. Found a tricky error in production? Simply save it to a test set and use it directly in the playground to debug and fix it instantly!
Comprehensive Evaluation Suite
Replace guesswork with hard evidence using Agenta's robust evaluation framework! Create a systematic process to run experiments, track results, and validate every single change before deployment. The platform supports any evaluator you need, including LLM-as-a-judge, built-in metrics, or your own custom code. Crucially, you can evaluate the full trace of complex agents, testing each intermediate reasoning step, not just the final output. Plus, seamlessly integrate human evaluations from domain experts directly into your workflow!
Deep Observability & Debugging
Gain unparalleled visibility into your AI systems with Agenta's observability tools! Trace every single request to find the exact point of failure when things go wrong, turning debugging from a guessing game into a precise science. Annotate traces collaboratively with your team or gather direct feedback from end-users. The best part? You can turn any problematic trace into a test case with a single click, creating a powerful, closed feedback loop that continuously improves your application's reliability!
Seamless Team Collaboration
Break down silos and bring product managers, domain experts, and developers into one cohesive workflow! Agenta provides a safe, intuitive UI for non-technical experts to edit prompts and run experiments without touching code. Empower everyone to run evaluations and compare results directly from the interface. With full parity between its API and UI, Agenta integrates both programmatic and manual workflows into a single, central hub that accelerates alignment and decision-making across your entire team!
OpenMark AI
Simple Task Description
No technical jargon here! Just describe the task you want to benchmark in plain language. OpenMark AI translates your requirements into actionable tests against over 100 AI models, making it accessible for everyone.
Real-Time Results Comparison
See results side-by-side with real API calls to the models! Forget about cached marketing numbers; our platform delivers accurate performance metrics that help you make informed decisions based on real-world data.
Cost and Performance Analysis
Worried about spending too much? OpenMark AI provides detailed insights into the cost-per-request for each model. Compare quality relative to cost and identify which model gives you the best bang for your buck, ensuring maximum return on investment.
Consistency Monitoring
Will your chosen model deliver the same quality every time? With OpenMark AI, you can test for stability by running the same task multiple times and observing output variance, so you can rest assured that your AI feature will perform reliably.
Use Cases
Agenta
Accelerating Agent & Chatbot Development
Teams building conversational agents or complex chatbots can use Agenta to rapidly prototype, test, and refine their LLM pipelines! The unified playground allows for quick A/B testing of different prompts and reasoning models, while the full-trace evaluation ensures every step of the agent's logic is sound. Collaboration features mean domain experts can directly tweak conversation tones or factual responses, leading to faster iterations and a more reliable final product that's ready for user traffic!
Enterprise LLM Application Lifecycle Management
Large organizations struggling with scattered prompts and siloed teams can implement Agenta as their central LLMOps command center! It provides the structured process needed to manage the entire lifecycle of multiple LLM applications, from initial experimentation to production monitoring. By centralizing prompts, evaluations, and traces, it establishes governance, enables reproducible experiments, and gives leadership clear visibility into performance and ROI, turning chaotic development into a streamlined operation!
Building Evaluated & Validated AI Features
Product teams integrating LLM features into existing software can use Agenta to ensure every release is high-quality and reliable! Before any update goes live, teams can run automated evaluations against comprehensive test sets and gather human feedback from stakeholders. This evidence-based approach replaces "vibe testing," guaranteeing that new features actually improve performance and don't introduce regressions, allowing for confident and frequent deployment of AI-powered capabilities!
Debugging & Improving Production Systems
When a live LLM application starts behaving unexpectedly, Agenta turns crisis management into a streamlined diagnostic process! Engineers can immediately inspect traced requests to pinpoint the exact failure in a chain of thought or API call. They can save errors as test cases, debug them in the playground, and validate fixes with the evaluation suite before deploying a patch. This closes the loop between production issues and development, dramatically reducing mean-time-to-repair!
OpenMark AI
Model Selection for Development
Use OpenMark AI to benchmark various models for your specific tasks, ensuring that you choose the best one for your development needs. Validate their performance before integrating them into your applications!
Cost-Effective AI Solutions
Are you looking to optimize your AI budget? OpenMark AI enables you to compare the cost and quality of different models, helping you make smarter financial decisions while still achieving top-notch performance.
Consistency Testing for Reliability
In industries where reliability is key, use OpenMark AI to ensure that your model maintains consistent output quality across multiple runs. This is crucial for applications in healthcare, finance, and more!
Pre-Deployment Validation
Before launching an AI feature, run benchmarks on OpenMark AI to validate your model choices. Make sure you have the right fit for your workflow, minimizing the risk of post-deployment issues and ensuring user satisfaction.
Overview
About Agenta
Agenta is the dynamic, open-source LLMOps platform designed to transform how AI teams build and ship reliable, production-ready LLM applications! It tackles the core chaos of modern LLM development head-on, where prompts are scattered, teams work in silos, and debugging feels like a guessing game. Agenta provides a unified, collaborative hub where developers, product managers, and subject matter experts can finally work together seamlessly. It centralizes the entire LLM workflow, enabling teams to experiment with prompts and models, run rigorous automated and human evaluations, and gain deep observability into production systems. The core value proposition is powerful: move from unpredictable, ad-hoc processes to a structured, evidence-based development cycle. By integrating prompt management, evaluation, and observability into one platform, Agenta empowers teams to iterate faster, validate every change, and confidently deploy LLM applications that perform consistently and reliably. It's the single source of truth your whole team needs to turn the unpredictability of LLMs into a competitive advantage!
About OpenMark AI
Welcome to OpenMark AI, the ultimate web application designed for task-level LLM benchmarking! Gone are the days of guesswork when selecting the right AI model for your projects. With OpenMark AI, you can easily describe your testing needs in plain language and run comparisons against a multitude of models—all in one session! Our platform allows developers and product teams to evaluate models based on cost per request, latency, scored quality, and stability across repeated runs, ensuring you can see the variance in outputs rather than relying on a single lucky result. No need to juggle multiple API keys; we handle the backend for you! OpenMark AI is built for those who prioritize cost efficiency and consistent performance. Whether you are validating a model before launching an AI feature or looking to optimize your workflow, we’ve got you covered! Plus, with both free and paid plans available, getting started is a breeze!
Frequently Asked Questions
Agenta FAQ
Is Agenta really open-source?
Yes, absolutely! Agenta is a fully open-source platform under the Apache 2.0 license. You can dive into the code on GitHub, self-host the entire platform, and even contribute to its development. Hundreds of developers are actively involved in the community, and we believe in building transparent, vendor-neutral infrastructure that gives teams full control over their LLMOps stack!
How does Agenta handle different LLM providers and frameworks?
Agenta is designed to be model-agnostic and framework-flexible! It seamlessly integrates with all major providers like OpenAI, Anthropic, and Cohere, allowing you to use the best model for each task without lock-in. It also works effortlessly with popular frameworks like LangChain and LlamaIndex, fitting into your existing tech stack without requiring a painful rewrite. You bring your models and code; Agenta brings the management and evaluation superpowers!
Can non-technical team members really use Agenta effectively?
They sure can! A core mission of Agenta is to democratize LLM development. We provide an intuitive web UI that allows product managers, subject matter experts, and other non-coders to safely edit prompts, run experiments, and evaluate results without writing a single line of code. This bridges the gap between technical implementation and domain knowledge, unlocking collaboration and speeding up the iteration cycle dramatically!
What does the evaluation process look like in Agenta?
Agenta's evaluation process is both powerful and flexible! You start by creating test datasets (which can be built from production traces). You then configure evaluations using AI judges, code-based metrics, or human input. The system runs your experiments (different prompts/models) against these tests, providing detailed, comparable results. You can evaluate the entire reasoning trace of an agent, not just the final output, giving you deep insight into what works and what breaks, so you can deploy with confidence!
OpenMark AI FAQ
How does OpenMark AI work?
OpenMark AI allows you to describe tasks in simple language, run benchmarks against a wide array of AI models, and provides real-time performance data to help you make informed choices.
Do I need to configure API keys to use OpenMark AI?
No! OpenMark AI handles all the backend API integrations for you. You can start benchmarking without the hassle of setting up separate API keys for different models.
Can I test multiple models at once?
Absolutely! You can run benchmarks against over 100 models in one session, allowing for comprehensive comparisons and insights into which model performs best for your specific needs.
Is there a free version of OpenMark AI?
Yes! OpenMark AI offers both free and paid plans, giving you the flexibility to choose a subscription that fits your needs while providing access to powerful benchmarking capabilities.
Alternatives
Agenta Alternatives
Agenta is a dynamic, open-source LLMOps platform designed to help teams build and manage reliable AI applications together! It falls squarely into the category of development tools that bring order to the chaos of LLM workflows, centralizing experimentation, evaluation, and observability. Teams often explore alternatives for various reasons! You might be looking for a different pricing model, a specific feature set, or a platform that aligns with your team's unique size, technical stack, or deployment preferences. The search for the perfect fit is a smart move! When evaluating options, focus on finding a solution that empowers your entire team! Look for robust collaboration features, a strong evaluation framework for evidence-based decisions, and deep production observability. The goal is to find a platform that turns the unpredictability of LLMs into your team's superpower!
OpenMark AI Alternatives
OpenMark AI is a cutting-edge web application designed for task-level benchmarking of large language models (LLMs). It allows users to easily compare over 100 models based on crucial metrics like cost, speed, quality, and stability—all in one place! As developers and product teams explore the world of AI, they often seek alternatives to tools like OpenMark AI for various reasons, including pricing structures, specific feature sets, or unique platform requirements. When searching for an alternative, it's essential to consider factors such as the breadth of model support, the ability to perform side-by-side comparisons, and the overall user experience. A great alternative will not only provide accurate and reliable results but also offer flexibility to meet your specific needs without unnecessary complexity!