Friendli Engine
About Friendli Engine
Friendli Engine is designed for developers and businesses seeking efficient generative AI models. Leveraging unique technologies like Iteration Batching and Friendli TCache, it ensures rapid LLM inference while significantly lowering costs. Friendli Engine simplifies the process of deploying complex AI models for various applications.
Friendli Engine offers flexible pricing plans tailored to different user needs. From free trials to premium subscriptions, users can choose a plan that suits their level of engagement. Special discounts may apply for higher-tier plans, presenting enhanced features and capabilities for advanced generative AI tasks.
Friendli Engine features an intuitive user interface designed for seamless navigation. The layout promotes a user-friendly experience, allowing quick access to key features such as Dedicated Endpoints and serverless solutions. Customizable options empower users to optimize their generative AI models effortlessly within the platform.
How Friendli Engine works
To start using Friendli Engine, users can easily sign up and access its suite of features. After onboarding, they navigate through a streamlined dashboard, selecting between Dedicated Endpoints, Containers, or Serverless options to deploy their models. The platform guides users in fine-tuning and optimizing their AI applications effortlessly.
Key Features for Friendli Engine
Fast LLM Inference
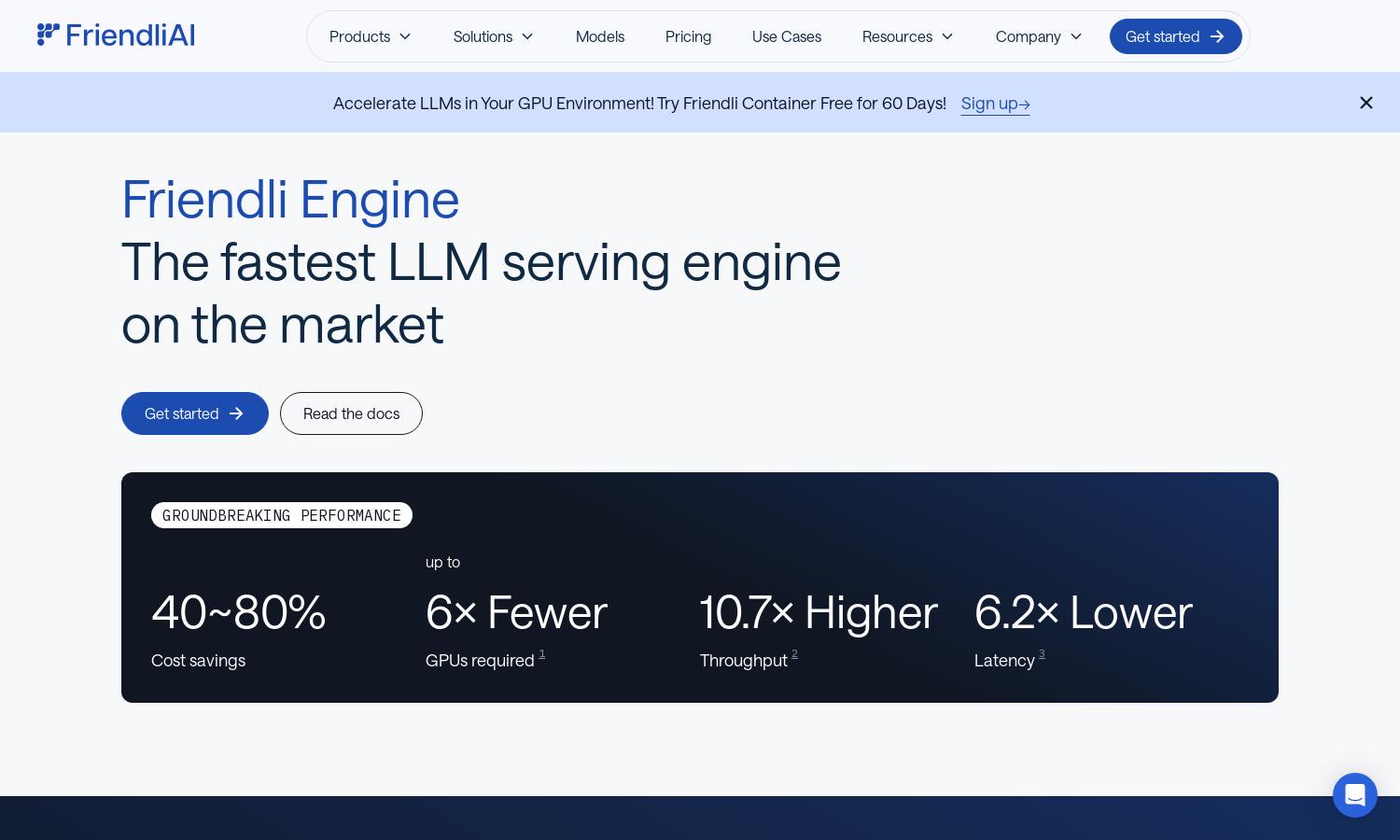
Friendli Engine specializes in fast LLM inference, achieving 50~90% cost savings and significantly higher throughput. This key feature helps users leverage advanced technology to complete tasks quickly while optimizing GPU resources, making it a game-changer in the generative AI landscape.
Multi-LoRA Support
With its Multi-LoRA support, Friendli Engine allows simultaneous operation of multiple LoRA models on fewer GPUs. This innovative capability enhances the accessibility and efficiency of LLM customization, enabling users to deploy complex models while minimizing hardware costs and maximizing results.
Smart Caching
Friendli TCache is a unique feature of Friendli Engine that intelligently stores frequently used computational results. This caching significantly reduces GPU workload and optimizes Time to First Token, enhancing the overall LLM inference process and providing substantial performance improvements.